The Legal Landscape of AI Generated Intellectual Property
Navigating Copyright in Our AI-Driven World
The digital revolution has forced copyright law, traditionally designed for human creators, to confront challenging new questions about artificial intelligence. As machines generate increasingly sophisticated creative outputs - from musical compositions to visual artworks - legal systems worldwide struggle to define proper attribution. The central dilemma revolves around whether copyright should protect works where human involvement is minimal or indirect.
Originality remains the cornerstone of copyright protection, requiring human creative expression. Yet AI's capacity to produce works that appear original without direct human authorship creates a legal gray area. Courts and legislators now face the difficult task of deciding whether to extend copyright to these machine-generated creations or maintain strict human authorship requirements.
Assessing Human Influence in AI Creation
Legal determinations often hinge on the nature of human participation in the creative process. When developers provide extensive training, parameters, and guidance to an AI system, courts may recognize their creative contribution. The more deliberate and specific the human input, the stronger the case for traditional copyright protection.
However, systems operating with substantial autonomy present greater challenges. Legal experts must carefully examine the creative chain - from initial programming to final output - to determine where and how human creativity manifests. This analysis often requires technical understanding of machine learning processes alongside traditional copyright principles.
Tool or Collaborator: The AI Identity Crisis
The legal framework depends heavily on whether we view AI as an instrument or creative partner. Traditional tools like cameras or word processors clearly serve human creators, but AI systems that independently make creative decisions complicate this paradigm.
Emerging technologies force us to reconsider fundamental assumptions about creativity and authorship. Some jurisdictions have begun developing new categories for computer-generated works, while others maintain that only human creations qualify for protection. This legal patchwork creates uncertainty for creators and businesses working with AI.
Training Data: The Copyright Minefield
The materials used to train AI systems present additional legal complications. Many datasets incorporate copyrighted works, raising questions about fair use and derivative works. Recent lawsuits have highlighted the risks of using protected content without proper authorization.
Legal experts emphasize the importance of carefully vetting training materials and considering licensing options. As litigation in this area increases, companies investing in AI development must prioritize copyright compliance throughout the training process.
Urgent Need for Legal Evolution
The rapid advancement of AI technology has outpaced existing copyright frameworks. Policymakers face pressure to develop clearer guidelines that balance innovation with creator rights. Some suggest creating new categories of protection specifically for AI-assisted works, while others advocate for maintaining traditional requirements.
Global Challenges Require International Solutions
Copyright laws vary significantly across borders, creating complications for AI-generated content distributed internationally. Without coordinated efforts, conflicting national approaches could stifle innovation and create legal uncertainty.
Multinational organizations have begun discussing harmonized standards, but progress remains slow. As AI becomes ubiquitous in creative fields, the need for international consensus grows more pressing. Companies operating globally must navigate this evolving landscape carefully.
The Critical Foundation of Data in Machine Learning
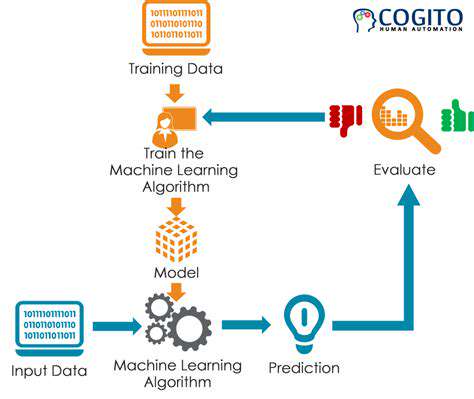
Data's Central Role in AI Development
Machine learning models fundamentally depend on the data they're given - the quality of inputs directly determines the quality of outputs. Professionals in the field often compare data to raw materials in manufacturing; no matter how advanced the equipment, poor materials yield poor products. Proper data preparation often consumes more time and resources than actual model development.
The diversity of data types - from structured numerical data to unstructured text and images - requires specialized handling techniques. Teams must carefully match preprocessing approaches to their specific data characteristics and project goals.
Training Sets: The Educational Foundation
These carefully selected data subsets serve as the primary teaching material for machine learning algorithms. The selection process requires balancing multiple factors: sufficient volume to teach patterns, appropriate diversity to prevent bias, and relevance to real-world applications.
Experienced practitioners know that a well-constructed training set often matters more than algorithmic sophistication. The training data essentially defines what the model will learn, making its design one of the most critical steps in development.
Quality Control in Data Preparation
Flaws in training data inevitably propagate through to model performance. Teams must implement rigorous quality checks for accuracy, completeness, and consistency. Common issues like missing values or measurement errors require careful handling to avoid distorting results.
Advanced techniques like anomaly detection help identify problematic data points, while thoughtful imputation strategies can address gaps without introducing bias. Data cleaning represents both an art and science in machine learning pipelines.
Addressing Bias in Machine Learning
Unintended bias in training data can lead to discriminatory or inaccurate models with real-world consequences. The financial and healthcare sectors have seen particularly concerning examples where biased data produced unfair outcomes.
Proactive approaches include diversity audits of training sets and statistical techniques to identify and mitigate bias. Responsible AI development requires ongoing vigilance against bias throughout the model lifecycle.
Balancing Quantity and Quality
While larger datasets generally improve performance, the relationship isn't linear. There comes a point of diminishing returns where additional data provides limited benefit while increasing computational costs. Smart sampling techniques can sometimes achieve comparable results with smaller, well-curated datasets.
Teams must also guard against overfitting, where models memorize training data rather than learning generalizable patterns. Regularization techniques and validation protocols help maintain this crucial balance.
Ethical Data Handling Practices
Increasing regulation worldwide demands careful attention to data privacy and security. Techniques like differential privacy and federated learning offer ways to develop models while protecting sensitive information. Compliance with standards like GDPR requires building privacy considerations into every stage of development.
Forward-thinking organizations now view ethical data practices as both legal requirements and competitive advantages. Consumers increasingly favor companies that demonstrate responsible data stewardship.
Continuous Performance Monitoring
The true test of any training set comes when models encounter real-world data. Continuous monitoring helps identify when models begin to drift from their original performance benchmarks. This feedback loop allows teams to update training data and retrain models as conditions change.
Sophisticated deployment pipelines now incorporate automated monitoring and retraining capabilities, recognizing that model maintenance is an ongoing process rather than a one-time event.
Read more about The Legal Landscape of AI Generated Intellectual Property








Hot Recommendations
- Immersive Culinary Arts: Exploring Digital Flavors
- The Business of Fan Funded Projects in Entertainment
- Real Time AI Powered Dialogue Generation in Games
- Legal Challenges in User Generated Content Disclaimers
- Fan Fiction to Screenplays: User Driven Adaptation
- The Evolution of User Driven Media into Global Entertainment
- The Ethics of AI in Copyright Protection
- Building Immersive Narratives for Corporate Training
- The Impact of AI on Music Discovery Platforms
- AI for Audience Analytics and Personalized Content